The Most Common Unit Testing Mistakes

I’ll start with a not-so-controversial take – 100% line coverage is not a smart goal. It’s not a metric worth optimizing for. I do like tools that calculate it and visually show lines/branches that are not covered. I find this to be quite helpful as it helps me catch important edge cases, but that’s the end of it.
Teams who enforce this rule in their codebase often end up having a lot of tests that don’t bring much value. They write tests that ensure full coverage, but often those tests don’t include any interesting edge cases or scenarios that would catch sneaky regressions.
This is mistake number one – caring about metrics instead of the purpose and benefit of the tests. As I said, I doubt this is a controversial opinion, but for some reason, many teams make this mistake. And once the team reaches 99+% coverage, there’s a certain amount of peer pressure to continue with this practice – despite diminishing returns.
Let’s move on to other common problems and I promise that by the end you will see a common thread to all of these.
Mistake #1: Testing Implementation Instead of Behaviour
The next most common mistake is testing implementation details instead of behaviour. Before we get there, a small digression!
This is perhaps where I get into some controversial territory, but one way I like to think of the unit of code being tested (e.g the function or class method) is as a black box. This helps me completely forget about the internals of the method and I find that is usually the better mental model to use. We will soon see that it’s not always possible to actually treat a unit test as a black box (hint: external dependencies), but we can definitely try!
This is at odds with a lot of popular advice that views units as a white box – you know the implementation and the tests are a sort of spec. (But even then there is an agreement that assertions should not focus on internals.)
Prominent figures like Kent Beck have called this a false dichotomy – there is no one true answer here. Like many things, context matters and things depend based on the organization, the project, the people, etc.
In my experience, especially working at companies with multiple teams, the black box mental model pays dividends and helps you write software that is meant to be reused and leveraged across projects and teams. (But if you’re a small startup racing to find market-fit then perhaps you have more important things to worry about!)
So to summarize: when unit testing we know the inputs, the type of the output, and the behavior expected of the functionality. We should try to forget about the internals of it. When we test behaviour correctly we ensure that tests remain relevant and useful as the code evolves.
Let’s look at some examples of this mistake. Let’s start off with this snippet:
test('calculateNewUserDiscount applies a 10% discount to the order', () => {
const cart = new ShoppingCart([
{ item: 'Shirt A', price: 2000 },
{ item: 'Shirt B', price: 3400 },
]);
const total = calculateNewUserDiscount(cart);
expect(total).toEqual(5060);
});
The mistake should be pretty clear – the 10% discount is an internal implementation detail. The behaviour is the fact that there is a discount that has to be calculated based on our cart, but the specific value of 10% is an implementation detail. So the right assertion could be:
const totalPreDiscount = 5400;
const total = calculateNewUserDiscount(cart);
expect(total).toBeLessThanOrEqual(totalPreDiscount);
I’d assume that there is a chance that the user discount is 0%, so asserting that it is less than or equal to the total sum makes sense. But is a test like this useful?
It seems that in this example we’ve run into a case of bad design. And I think this is a benefit in itself – we could have gone with option #1 and left it there. Instead, we are now rethinking if we can refactor this and improve the overall design.
Let’s look at another example of testing implementation over behaviour.
// our unit of code
const prepareAndScheduleJob = (params) => {
const validationResult = validateParams(params);
if (validationResult.failed) {
return { error: 1, message: validationResult.errorMessage };
}
const jobDefinition = prepareDefinition(params);
const scheduleResult = await scheduleJob(jobDefinition);
if (scheduleResult.failed) {
return { error: 2, message: scheduleResult.errorMessage };
}
return { error: null, jobId: scheduleResult.id };
}
// our test
test('prepareAndScheduleJob successfully schedules a job', async () => {
const testParams = { /** some fields */}
scheduleJobMock.mockReturnValueOnce({ failed: false, id: '1234' });
const result = prepareAndScheduleJob(testParams);
expect(jobDefinitionSpy.calls.length).toBe(1);
expect(result.id).toBe('1234');
});
I think you know where this is going. The first assertion is completely unnecessary. If the function is modified so that this method is no longer used, our unit test will fail for no reason. The behaviour has nothing to do with whether or not prepareDefinition exists.
Here’s an example of testing implementation in our scheduleJob function:
// our unit of code
const scheduleJob = (definition) => {
const id = generateUuidV4();
const message = makeMessage(definition);
const result = await snsPublisher.publishMessage(message);
if (result.failed) {
return { error: true, message: result.error };
}
return { error: false, id: id };
}
// our test
test('scheduleJob successfully schedules a job via SNS', async () => {
const definition = { /** some fields */};
const expectedSnsMessage = { /** some fields */ };
generateUuidV4Mock.mockReturnValueOnce('1234');
snsPublisherSpy.publishMessage.spy();
const result = scheduleJob(definition);
expect(snsPublisherSpy.calls[0]).toBe(expectedSnsMessage);
expect(result.id).toBe('1234');
});
This example has a lot of things going wrong:
- The name of the test already leaks implementation details.
- We mock a function that generates an identifier for no reason – and we don’t even use the expected
uuid4format. - Instead of just mocking the call to SNS, we also spy on it and verify the input it received – which is an internal detail.
The worst thing about this unit test is how it’s technically trying to also test the makeMessage function – a completely different unit of code.
Don’t complicate it, your test can simply look like this:
test('scheduleJob successfully schedules a job', async () => {
const definition = { /** some fields */};
snsPublisherSpy.publishMessage.mock();
const result = scheduleJob(definition);
expect(result.id.length).toBeGreaterThan(0);
});
If for some reason the UUID V4 format was an important part of the behaviour (e.g this is an API with a strict public contract), then you could check for this explicitly:
expect(isUuidV4Format(result.id)).toBeTrue();
Does Mocking Break our Black Box Model?
As I hinted at the start – it does. Mocking, spying, and stubbing external dependencies via various Test Doubles is unavoidable. It is, however, not a departure from our principle of testing behaviour, not the implementation. Side effects, after all, are part of the behaviour and external dependencies (databases, file systems, other APIs) are part of your architectural boundary.
The problem comes in the lengths we sometimes go to in setting up all this mocking code. The invested effort can easily outweigh any benefits, which brings us to…
Mistake #2: Testing Way Too Much
Nobody ever got fired for buying IBM! And nobody ever gets into trouble for writing a lot of unit tests. And why not? They’re easy to do, make you feel extra safe, and running them doesn’t cost much. Does this argument sound reasonable? Let’s look at that in a bit more detail.
How Much Does a Test Cost?
Unit tests do have costs, which means that some sort of cost vs benefit analysis makes sense. Here are some examples of incurred costs:
- The time it takes to write it initially.
- The time it takes to rewrite them when things change.
- The time it takes to run them.
Arguably #1 should be low and writing unit tests becomes a habit for engineers after a while. And #2 might also sound like a benefit in disguise as some of those test failures might just have helped you catch a regression.
But what about the time it takes to run them? A single test is fast, but what happens when you have thousands of them?
Let’s do some napkin math. Imagine that:
- you have a team of 6 that makes 2 commits per day per person.
- you are using AWS CodeBuild to run unit tests before deploying to each stage (beta, gamma, prod)
- you are using
general1.mediumwhich costs $0.01 for 1 build minute. - your full test suite takes 15 minutes to run.
In a month with 21 work days, your engineers will make a total of 252 changes. Across three different environments, we will consume 252 * 3 * 15 = 11340 build minutes. This will cost us $113.4 per month. Over time this will increase due to more code being written.
Of course my dear reader, you are immediately optimizing:
- Why do we run the tests for each environment?
- Can we improve the speed of the testing infrastructure?
- Why run the full test suite and not just the impacted files?
No matter how much we optimize (and optimizing has its own cost of engineering time being invested!) it’s a fact that having fewer tests will be cheaper.
It’s a hard position to defend if I tell you to drop tests to save costs. That’s not what I’m going to argue, but I will say that it is quite reasonable to skip certain tests.
Here are my suggestions on what to skip:
- Tests that verify trivial things such as getters, setters, pass-through utilities, glue code without any logic, etc.
- Tests that test the underlying implementation details and/or private methods. (See the previous section, this is probably the most important bit.)
- Tests that "challenge" code with unrealistic/random/odd data – you won’t do it right and it’s a waste of time, instead if this is a need, you should build a dedicated fuzz testing mechanism.
- UI tests that target web/mobile elements and user interactions – this is usually a waste of time. You’ll be better off with a couple of E2E Cypress tests and an up-to-date Storybook playground. I’ve seen thousands of different React unit tests and they’ve produced very little value in my opinion.
- Tests that focus on verifying third-party code – this is quite a personal annoyance of mine. I’ve seen too many tests that check if some exponential retry/back-off library is actually retrying or tests that check if a date/time library is actually formatting the date/time as required. You control the exact version of these dependencies. They will not break overnight!
The real cost saving here is developer time. It’s a waste of time (and therefore money) for engineers to write these tests and, perhaps worse, to wait on these tests to run.
Mistake #3: Focusing on Unit Tests Instead of Integration
And thus we come to the crux of it all. Your time is better spent coming up with good integration and e2e tests, rather than going for 100% code coverage. Unit tests are easy to pull off and give us a warm and fuzzy feeling of accomplishment, but keeping most of them is useless.
Having a cup of unit tests is not a recipe for success. A better recipe would be 3/4 of a cup of unit tests, 2 tablespoons of integration tests, and a teaspoon of end-to-end tests.
What I am quoting is indeed the test pyramid. Conventionally, you’ve probably seen a lot of illustrations that look like this:
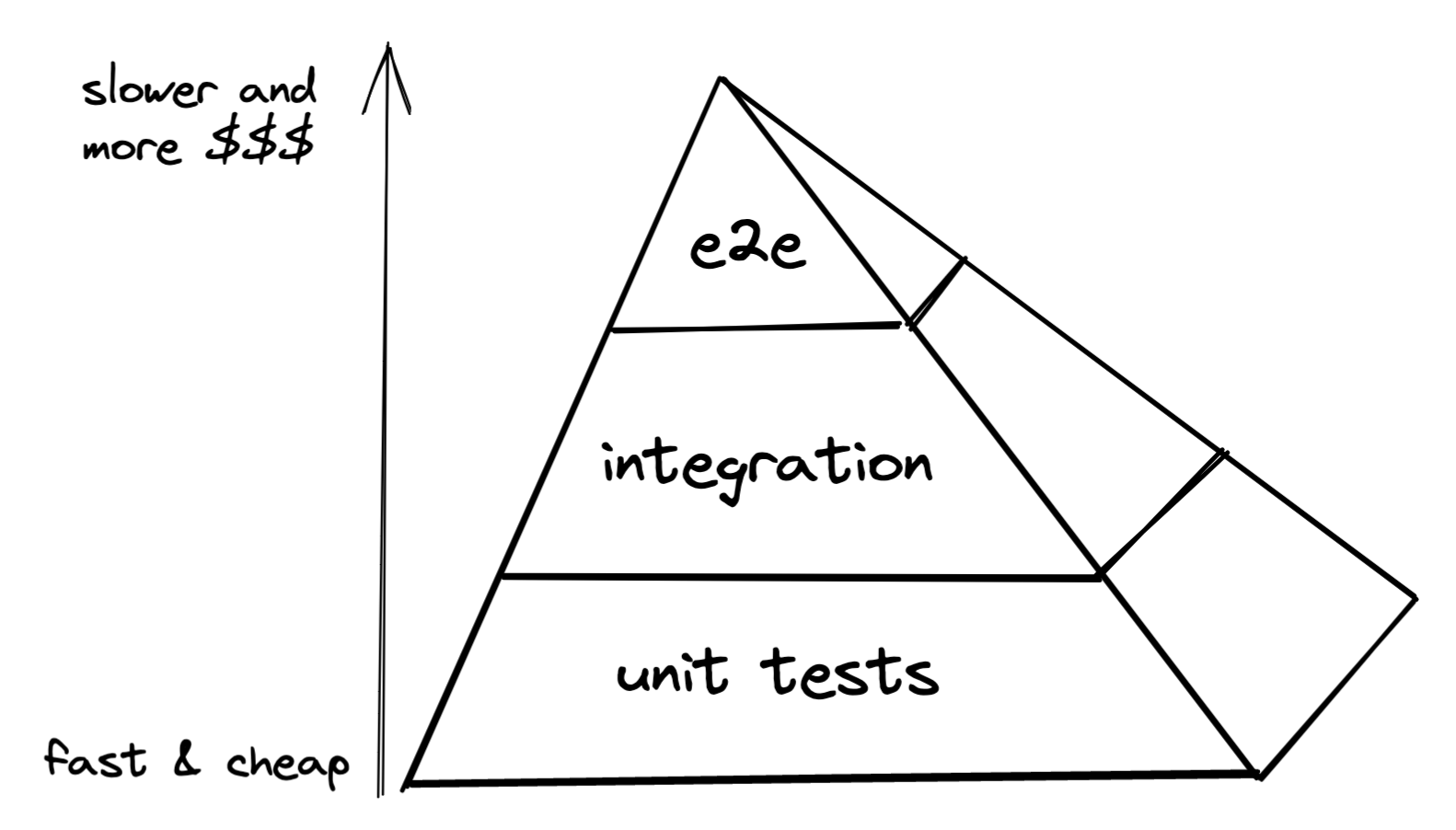
There’s a gap between each layer of the pyramid – it takes longer to create, run, and maintain integration and end-to-end tests. But my observation is that this gap is shrinking. More on that some other time.That’s enough about automated testing for now. If you’re tired of this, refresh your mind by learning more about Exploratory testing, a manual testing method that is actually worth practicing!




Comments ()